ML-системы: как научить машину мыслить самостоятельно

Материал подготовила команда VK Crowd
ML-системы: как научить машину мыслить самостоятельно
ML (Machine Learning) позволяет компьютерам решать задачи, находя закономерности в данных, что делает его формой искусственного интеллекта. Алгоритмы ML используются для анализа больших объёмов данных.
История
Понятие машинного обучения предложил американский исследователь Артур Самуэль, работавший в компании IBM. В 1959 году он разработал программу для игры в шашки, способную играть самостоятельно и обучаться без помощи человека. Американский нейрофизиолог Фрэнк Розенблатт создал первый нейрокомпьютер под названием перцептрон, который мог распознавать образы и предсказывать погоду, но компьютер сочли неспособным к обучению, и работа была заброшена. В 2011 году компания Google создала подразделение Google Brain, занимавшееся проектами в области ИИ, после чего Amazon и Microsoft тоже запустили свои платформы по машинному обучению. Также в этот период Facebook внедрила в работу алгоритм DeepFace, способный распознавать лица.
Принцип машинного обучения
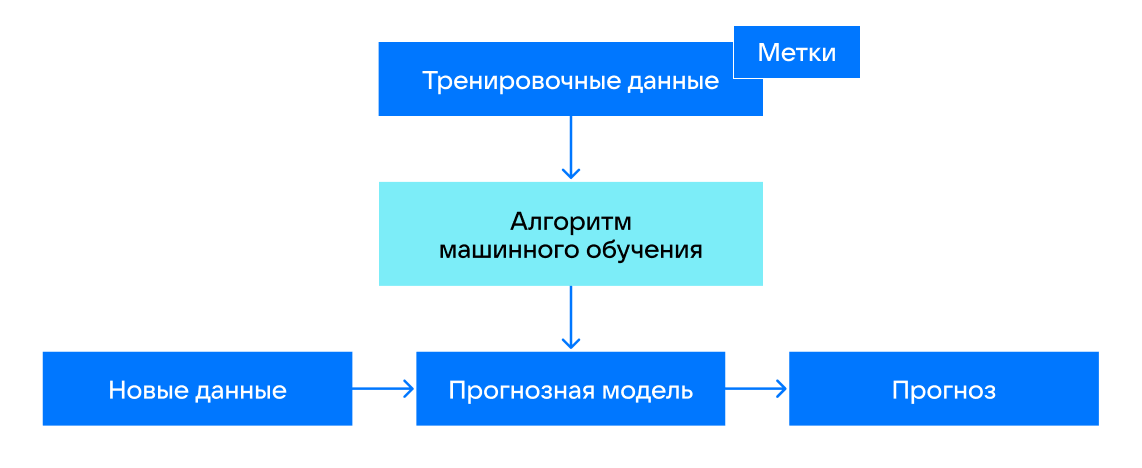
Машинное обучение — не то же самое, что программирование. Программисты создают для машин алгоритмы: прописывают чёткую последовательность действий, которая приведёт к нужному результату — в то время как ML-специалисты занимаются именно обучением модели. Они передают данные и пытаются объяснить, что нужно получить на выходе. У алгоритма нет заданного ответа, к которому нужно прийти: он только знает, как построить модель, отвечающую на поставленный вопрос. Машинное обучение позволяет создавать компьютеры и программы, которые думают как человек. Но при этом они не устают, не болеют, работают без перерывов и гораздо реже ошибаются. С помощью машинного обучения можно создавать сервисы и программы. От самых простых, которыми мы пользуемся в повседневной жизни — навигаторов, камер с распознаванием лиц, сервисов рекомендаций, — до сложных инструментов, которые нужны в промышленности или для безопасности.
Кто обучает ML-системы и как это происходит
Искусственный интеллект не способен что-то оценить или предсказать. Сперва его нужно научить работать с данными. После этого система сможет рассчитать нужное количество ткани для пошива коллекции одежды или предложить музыку, исходя из ваших предпочтений. Этим занимается специалист по машинному обучению, или же специалист по Data Science. Он собирает данные, размечает их, исследует, обучает модель и тестирует её. Существуют два основных подхода к обучению: с учителем или без.
Обучение с учителем
Такой тип подходит для классификации и регрессии. Системы, настроенные таким способом, могут узнать, на каких фотографиях изображён светофор, или просчитать ожидаемый доход от инвестиций через год. В этом случае специалист обучает машину на основе реальных примеров, чтобы она могла найти общие признаки и установить связи. Например, до начала работы системе могут дать набор данных, а в конце показать правильные результаты.
Обучение без учителя
Этот подход используется, когда невозможно заранее собрать размеченные данные. Такой тип обучения подходит для кластеризации данных: например, если нужно распознать в банковском приложении разные категории трат и на основе этого понять, какие ещё товары могут заинтересовать пользователя. Алгоритм самостоятельно ищет общие признаки и классифицирует полученные данные.
Какие навыки нужны, чтобы начать работать с ML-моделями
Специалистам по машинному обучению нужны технические навыки: • знание языка программирования (считается, что для этой цели больше всего подходят Python и R); • умение работать с линейной алгеброй; • понимание математических вероятностей и статистики; • знание основных алгоритмов машинного обучения; • умение работать с такими фреймворками, как Django и Flask.
Полезные материалы
Получить базу, необходимую для развития в ML, можно на открытых курсах от VK Education. Они включают в себя видеолекции, домашние задания и Q&A-сессии с экспертами VK. Их можно проходить в удобное для вас время.
• «Базовый Python»: vk.cc/cs79l7.
• «Алгоритмы и структуры данных»: vk.cc/cs79r5.
• «Введение в анализ данных»:vk.cc/cs79f9.
А если вам интересно на собственном опыте понять, как собираются большие датасеты, на которых обучаются нейросети, проходите вступительный тест программы по ML от VK Crowd: vk.com/welcome_crowd.
Вы также можете освоить тему своими силами. Для этого изучите теорию:
• Лекции по основам машинного обучения от GitBook. В них удобная структура: есть несколько теоретических уроков, практическая часть, модули и экзамен.
• Книгу «Математические основы машинного обучения и прогнозирования» Владимира Вьюгина. Пособие рассчитано на студентов и аспирантов и доступно излагает математические основы, необходимые для дальнейшей работы с машинным обучением.
• Учебник «Крупномасштабное машинное обучение вместе с Python». Авторы — Бастиан Шарден, Лука Массарон и Альберто Боскетти. В книге рассказывается о том, как обрабатывать большие файлы с помощью алгоритмов. Также объясняется, что такое вычислительная парадигма MapReduce и как работать с машинными алгоритмами на платформах Hadoop и Spark на языке Python.
• Книгу «Теоретический минимум по Big Data. Всё, что нужно знать о больших данных». Авторы — Анналин Ын и Кеннет Су. Каждому алгоритму посвящена отдельная глава, в которой не только объясняются основные принципы работы, но и даются примеры использования в реальных задачах. Большое количество иллюстраций и простые комментарии позволят легко разобраться в самых сложных аспектах Big Data.
Может быть интересно
 Статья
Статья Новость
Новость